簡単に機械学習の予測モデルを構築できるツール「Prediction One」試してみた
SONYから簡単に機械学習の予測モデルを構築できるツール「Prediction One」が公開されたので早速試してみました。
「誰でも数クリックで予測分析」が売りらしいので、私のようなド素人でも本当に簡単に予測分析ができるでしょうか。
インストール
Prediction Oneの「今すぐお申し込み」からファイルをダウンロードします。
インストールはひたすらクリックしていくだけなので割愛。
予測モデルを構築してみる
早速、予測モデルを構築してみます。
今回はKaggleの中でも特に有名な課題、「タイタニック号の生存予測」のデータを使ってみます。
Kaggleとは?
Kaggleとは、企業などがデータを投稿して、それに対して分析やモデリングをして最適なモデリングを競い合うサイトおよび運営会社のこと。
企業がデータを投稿してコンペを開催することで、優秀なデータサイエンティストを見つけるために利用したり、コンペに参加する人は自分の実力を図ったり勉強のために活用することができます。
タイタニック号の生存予測とは
kaggleのチュートリアル課題で最も有名な一つです。
タイタニック号乗客の性別、年齢、名前、チケット番号、支払った運賃などなどの情報から、その乗客がタイタニック号沈没事故で生き残ったかどうか予想します。
Titanic: Machine Learning from Disaster | Kaggleから、以下のCSVファイルをダウンロードしておきます。
- train.csv
生存結果が記載されている訓練用データ - test.csv
生存結果が記載されていない予測用データ
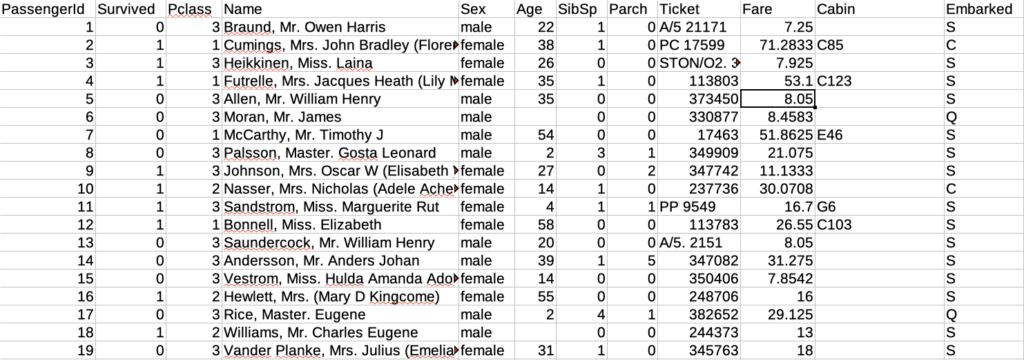
データの中身は以下のようになっています。
各カラムの説明は以下の通り。
- PassengerId – 乗客識別ユニークID
- Survived – 生存フラグ(0=死亡、1=生存)
- Pclass – チケットクラス
- Name – 乗客の名前
- Sex – 性別(male=男性、female=女性)
- Age – 年齢
- SibSp – タイタニックに同乗している兄弟/配偶者の数
- parch – タイタニックに同乗している親/子供の数
- ticket – チケット番号
- fare – 料金
- cabin – 客室番号
- Embarked – 出港地(タイタニックへ乗った港)
Prediction Oneを起動して、「新規プロジェクト」を作成します。
プロジェクト名を入力します。
新規モデルを作成
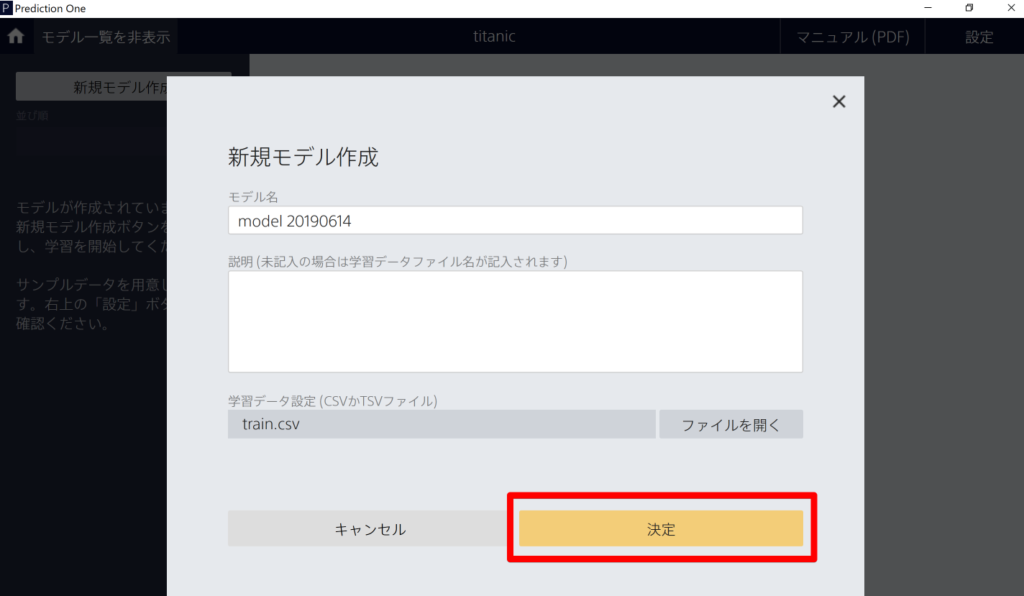
学習データに「train.csv」を読み込ませます。
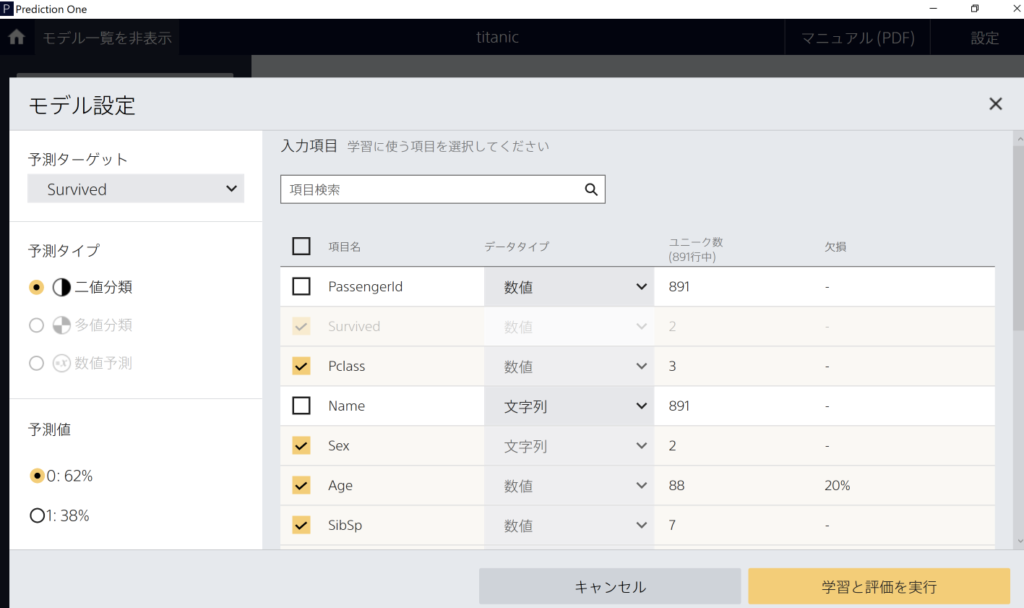
予測ターゲットを「Survived」にします。デフォルトでPassengerIdやNameなどは入力項目から外されています。「Age(年齢)」など一部の項目に欠損値が存在します。
本来であれば欠損値には適切な値を補完する必要がありますが、今回はこのまま予測してみます。
下にスクロールして、評価データの設定部分は、「学習データから自動抽出」と「必ず交差検証を行う」を選択して、「学習と評価を実行」をクリック。
学習が始まります。
学習が終了したら「OK」をクリック。
結果を確認してみる
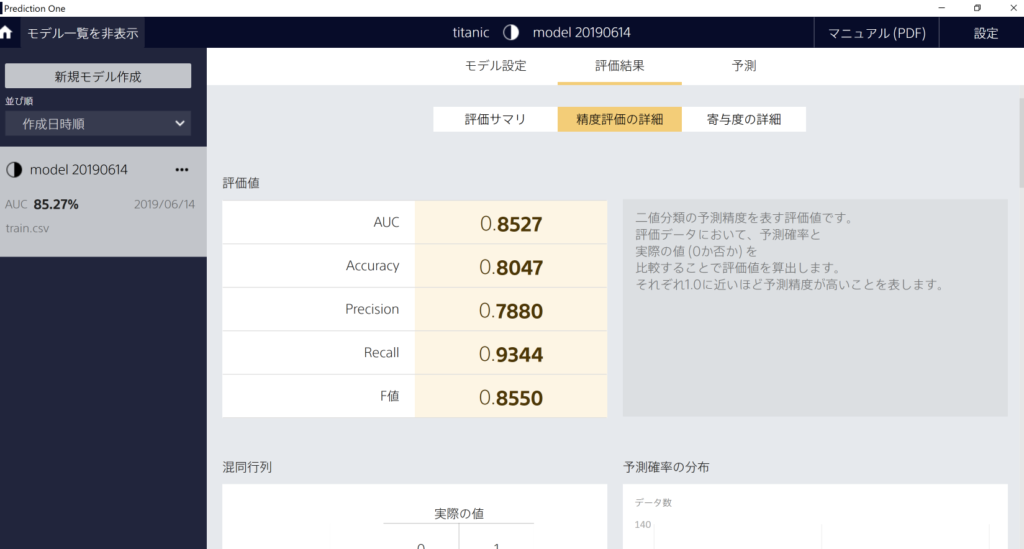
Accuracy(正解率)は、0.8527となりました。欠損値を無視しているわりには悪くない数値かと。
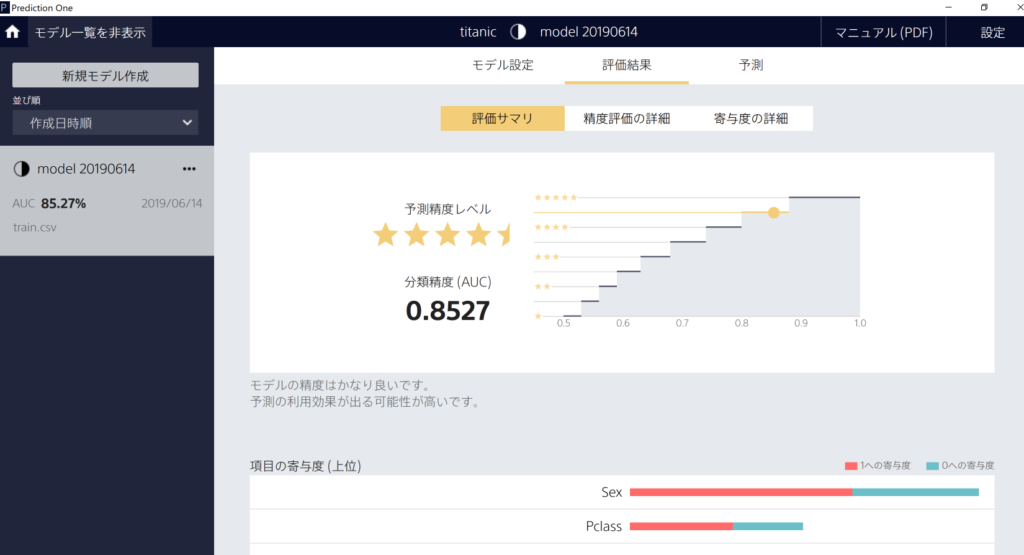
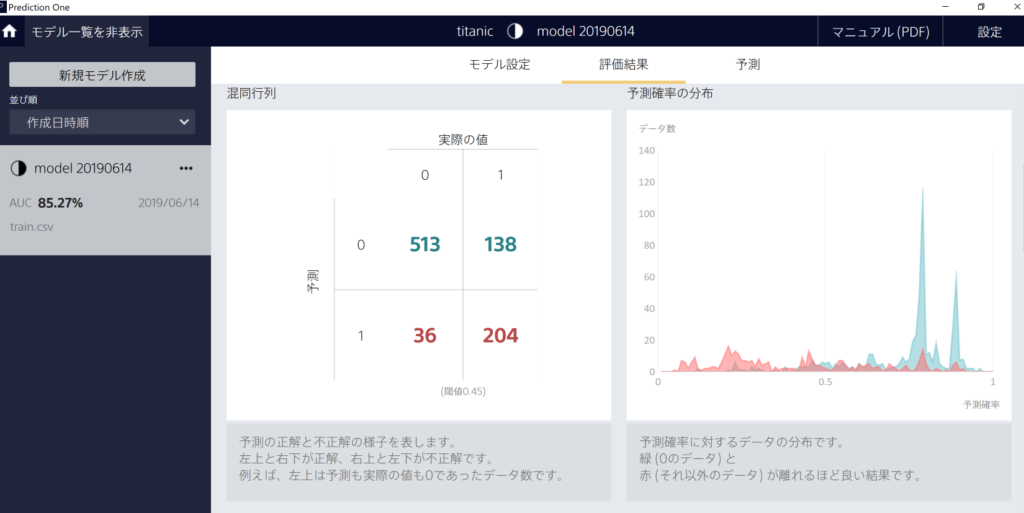
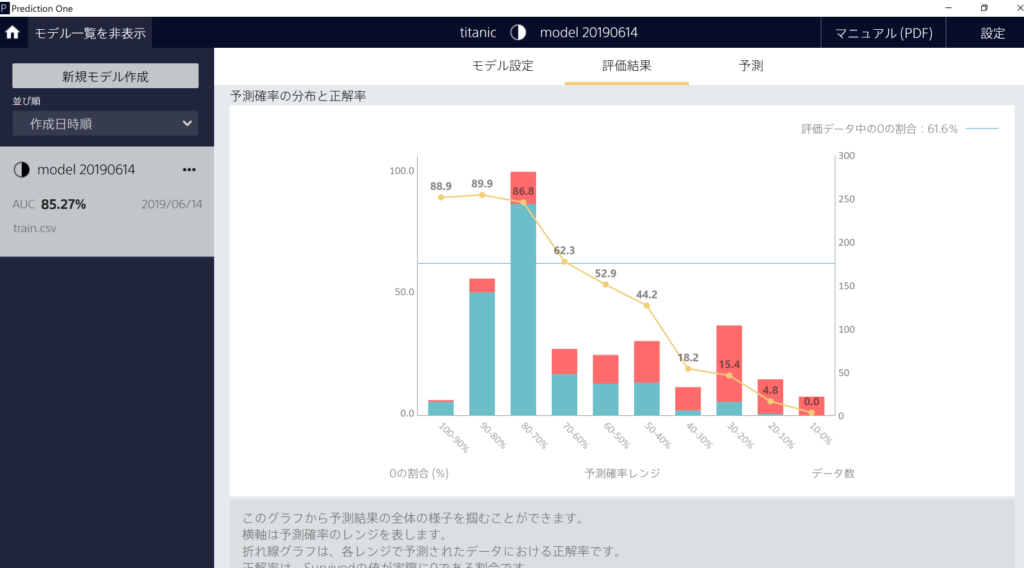
「精度評価の詳細」をクリックすると、さらに詳細な分析結果を見ることができます。
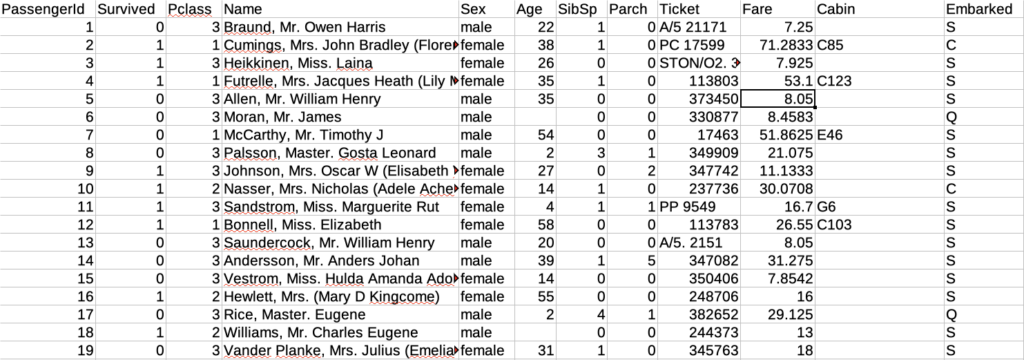
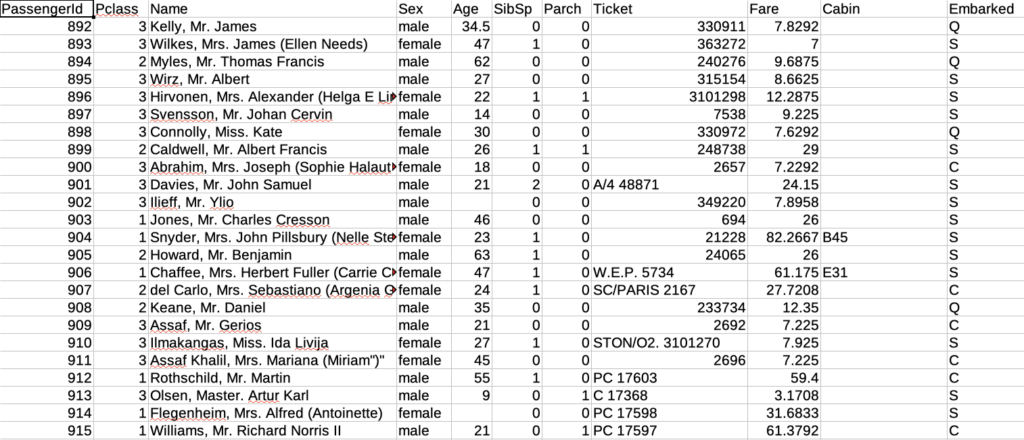
test.csvを予測してみる
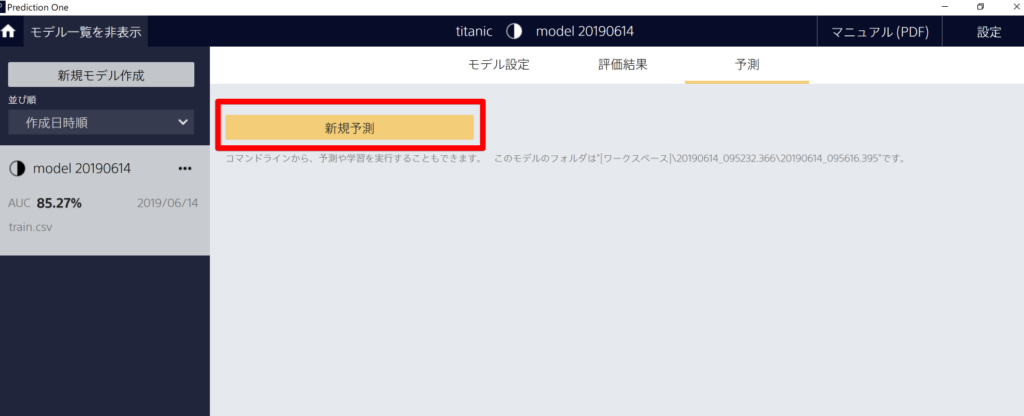
予測モデルの構築が完了したので、「test.csv」を実際に予測してみます。「予測」タブから「新規予測」をクリックします。
予測データに「test.csv」を指定して、「予測データを出力に追加」を選択してクリック。
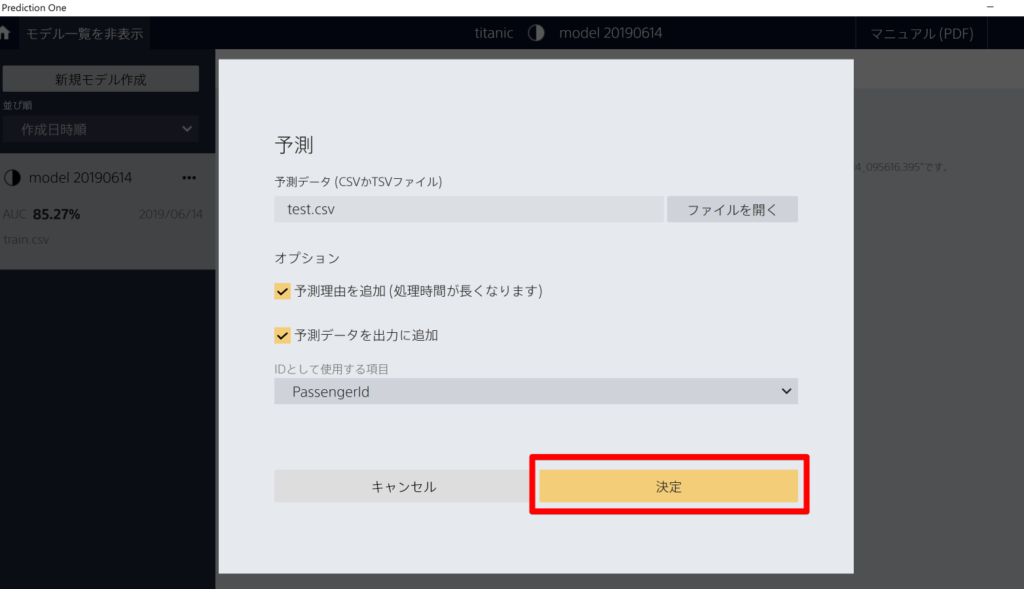
予測が完了するとプレビューが表示されますので、「予測結果を保存」をクリック
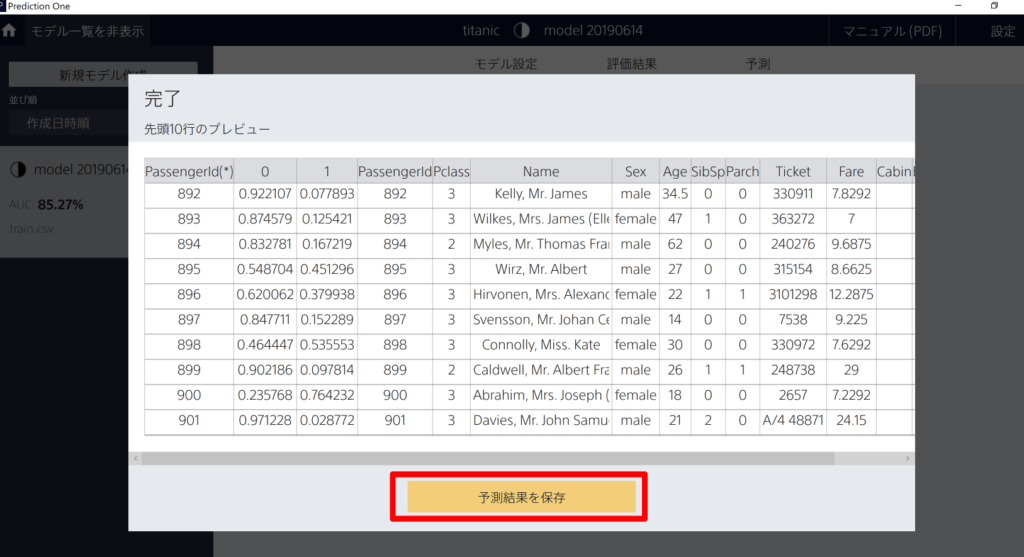
保存したCSVファイルは以下の様になっています。2行目と3行目に生存フラグ(0=死亡、1=生存)の確率が追加されています。
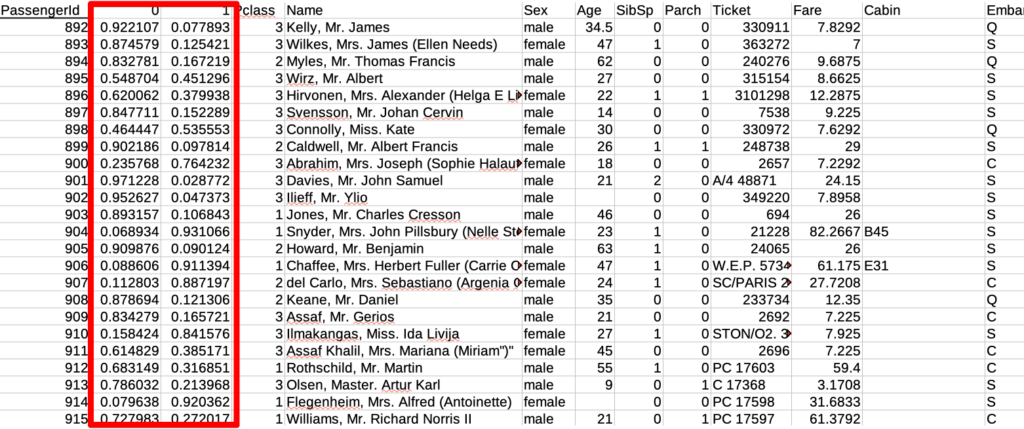
この予測データをKaggleへ投稿してみます。投稿するCSVは「PassengerId」と「Survived」のカラムのみである必要があるため、上記CSVを元に次のCSVファイルを作成しました。
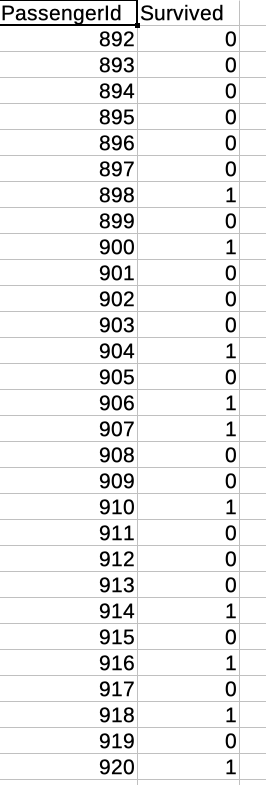
結果は以下の通り、「0.75598」というスコアになりました。
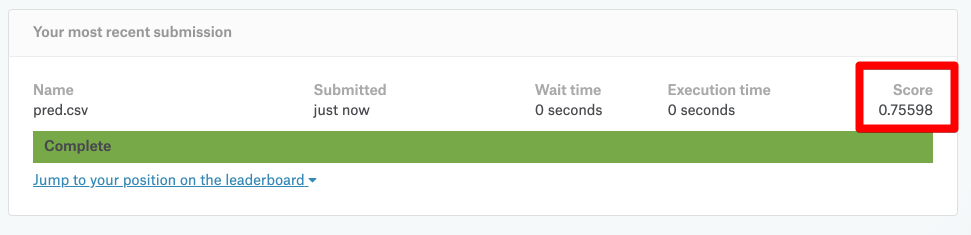
今回は「Prediction One」を使ってどこまで簡単に機械学習の予測モデルを構築できるのかが目的でしたので、欠損データを含めたデータの事前処理をまったくしていません。その割にはまぁまぁのスコアではないでしょうか。
直感的に操作できるのはもちろん、精度評価の詳細で様々な分析結果と結果を確認方法を説明してくれている点は、とても親切で機械学習の基本知識を知っている方には便利なツールじゃないかと思います。

