SplunkでTwitterのタイムラインを解析してみる
前回はSplunkにTwitterのタイムラインを取り込んだところまでやったので、今回はこのデータを使って分析してみたいと思います。
ユーザー別のMentios数
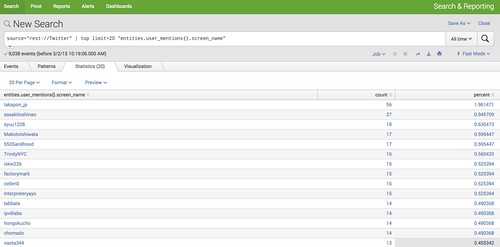
ツイートの中に含まれるユーザー別のMention数を集計してみます。
sourcetype="Twitter" | top limit=20 "entities.user_mentions{}.screen_name"
ソースタイプ「Twitter」のデータから、Mention名のFieldのトップ20を表示させます。
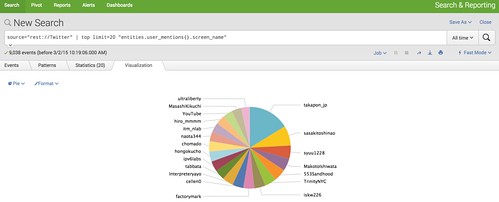
ビジュアル化する場合は「Visualiztion」タブを選択して、「Column」から適当なチャートを選びます。
以下は円グラフを選択してみた場合。
ハッシュタグ トップ20
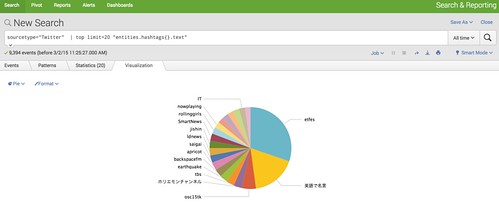
つづいて、ハッシュタグのトップ20を集計してみます。
sourcetype="Twitter" | top limit=20 "entities.hashtags{}.text"
これもハッシュタグのFieldがあるので、簡単に集計できます。
ビジュアル化するとこんな感じ。
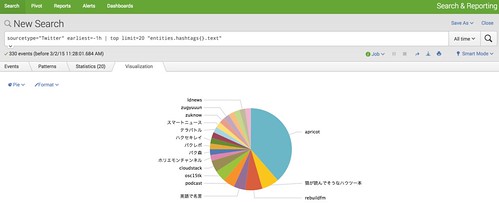
上記は全てのデータからハッシュタグを集計していますが、直近1時間のデータで集計したい場合は、「earliest=-1h」を付けて検索します。
sourcetype="Twitter" earliest=-1h | top limit=20 "entities.hashtags{}.text"
利用クライアント比率
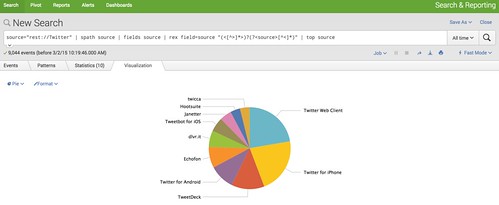
つづいて、利用しているクライアントの割合を集計してみます。
source="rest://Twitter" | spath source | fields source | rex field=source "(<[^>]\*>)?(?<source>[^<]\*)" | top source
「spath」はjsonなどからFieldを取り出す時に利用します。
source Fieldは「 TweetDeck」のように、hrefタグも含んでいるため、この文字列からクライアント名を抜き出すために、正規表現を利用しています。
時間帯別ツイート数
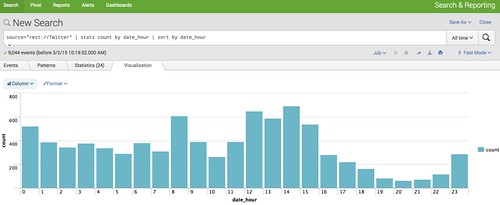
次は、時間帯別のつぶやき数を集計してみます。
source="rest://Twitter" | stats count by date_hour | sort by date_hour
「stats count by date_hour」で時間ごとのツイート数をカウントして、「sort by date_hour」でソートさせています。
ツイートのリアルタイム表示
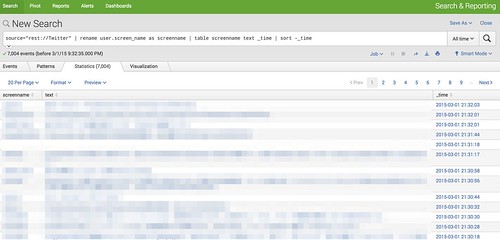
リアルタイムのツイートを表示させることもできます。
source="rest://Twitter" | rename user.screen_name as screenname | table screenname text _time | sort -_time
「rename user.screen_name as screenname」で、「user.screen_name」を表示させる時に「screenname」にリネームさせています。
結果をテーブルで、「table」、「screenname」、「text _time」の3つを表示させて、時間でソートさせて最新のツイートを常に1行目に表示させるようにしています。
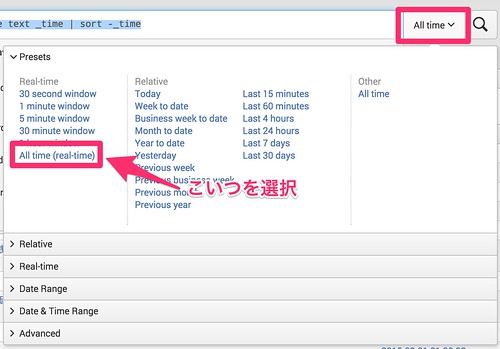
このままだと、検索しなければ更新してくれないので、リアルタイムに更新するようにするいは、検索条件で「All time (real-time)」を選択します。
これで、リアルタイムに結果が反映されます。
ダッシュボードに登録
Splunkには、解析の結果を一覧で見ることができる「ダッシュボード」というものがあります。
解析結果を表示させた状態で、右上の「Save As」->「Dashborad Panel」を選択
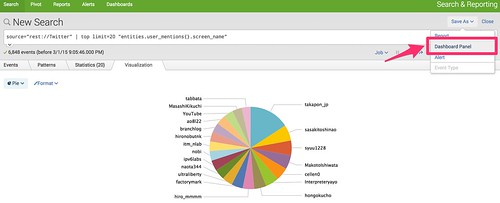
ダッシュボードの設定画面が出るので、新規で作成する場合は「New」、既に存在するダッシュボードに追加する場合は「Existing」を選択。
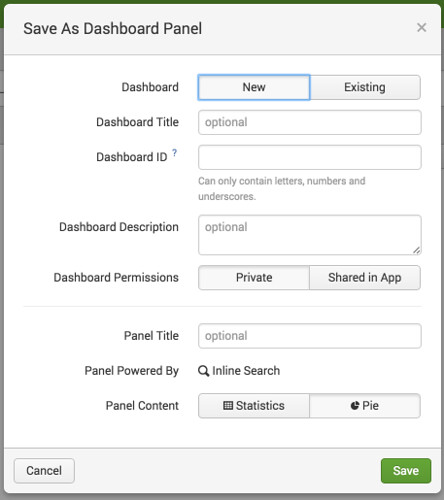
その他オプション項目を選択して「Save」すれば、トップ画面に表示されます。
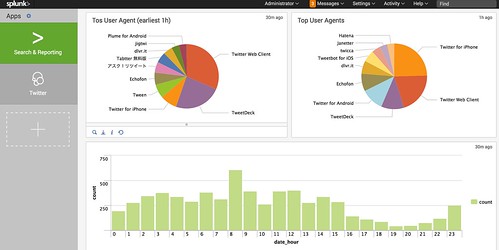
ダッシュボードは表示位置など細かく設定出来ますので、色々と弄ってみてください。
まとめ
今回、Twitterのデータを使っていろいろ解析してみました。
改めて思ったのは、データマイニングはデータを集めるだけでは意味が無くて、そのデータから何を導き出すか?がとても重要で、そのためには経験とセンスが必要な気がしました。
