Google Cloud Visionを使ってみた
Google Cloud Visionを使ってみた
以前から使ってみようみようと思っていた、Google Cloud Visionをようやく使ってみました。
Google Cloud Visionとは、
Google Cloud Vision API は、強力な機械学習モデルの能力を活用することで、画像の内容を認識し理解できるアプリケーションの開発を可能にします。Cloud Vision API は、画像を数千のカテゴリ(たとえば、「ヨット」「ライオン」「エッフェル塔」など)にすばやく分類する機能や、画像に映る個々の物体や人物の顔を解析する機能、画像に含まれる活字体の文字を認識して読み取る OCR 機能などを提供します。 この Cloud Vision API により、アプリケーションで扱う多数の画像のタグ付け、不適切な画像の検出、画像の意味の分析に基づく新しいマーケティング手法への応用が可能です。画像はリクエストの中に含めてアップロードすることで分析し、また Google Cloud Storage 上の画像ストレージとの連携も可能です。
Google Cloud Visionを使うと以下のようなことができるようです。
- 物体検知
画像に含まれる物体を検知し、乗り物から動物まで多数のカテゴリの中から分類できます。 - 有害コンテンツ検知
画像に含まれるアダルト コンテンツや暴力コンテンツのような有害コンテンツを検知します。 - ロゴ検知
画像に含まれるポピュラーな商品や企業のロゴを検知します。 - ランドマーク検知
画像に含まれるポピュラーな自然構造物や人工構造物を検知します。 - OCR
画像に含まれるテキストを認識して抽出します。幅広い言語に対応し、言語の自動判定も可能です。OCR ソフトを利用していたものが、クラウドで実現できます。 - 顔検知
画像に映る複数の人物の顔を検知し、感情の状態や帽子類の着用といった顔の主な属性も識別します。ただし、個人の認識には対応していません。
事前準備
まずは、Google Cloud Visionを使うための準備を行います。
Googleにログインした状態で、以下のサイトにアクセスします。
Vision API – 機械学習による画像認識, OCR | Google Cloud Platform
「無料トライアルを開始」をクリック
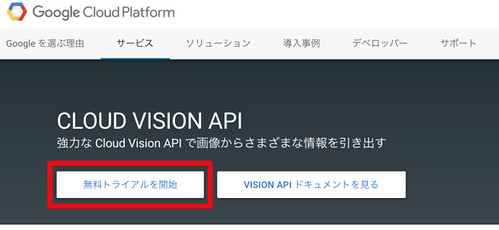
もろもろ設定して「同意して続行」をクリック
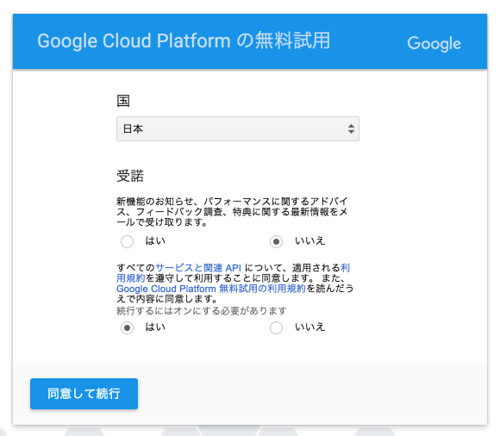
その後、住所やクレジットカードを入力しろ的なフォームがでてきますので適宜入力します。
クレジットカードの入力について
Google Cloud Visionを使うには、請求が発生しなくても事前にクレジットカードの登録が必要になります。1000回/月の問い合わせまでは無料で、以降は回数に応じて料金が設定されています。
無用にクレジットカード情報を登録したくないという方は辞めておきましょう。また、以降の手順を進める方は、すべて自己責任でお願いします。
Google Cloud Platformの画面が出てきますので、「プロジェクトを作成」をクリック。
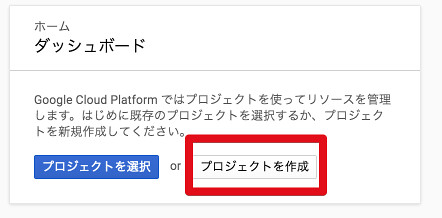
プロジェクト名を適宜入力して「作成」をクリック。
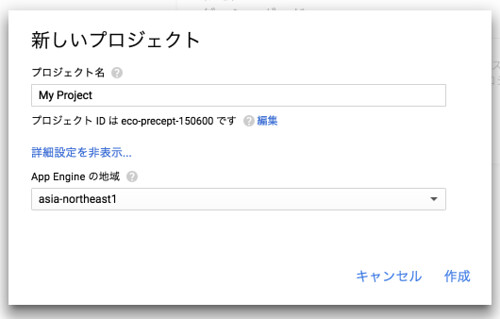
少し待てば、以下のように新しいプロジェクトが作成されます。
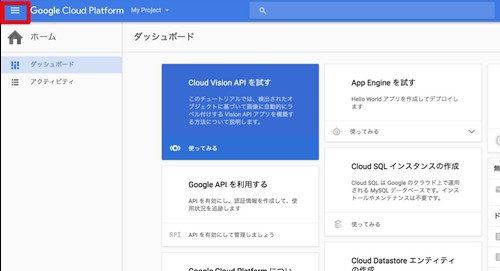
続いてCloud Vision APIを有効にします。左上のメニューボタンをクリックします。
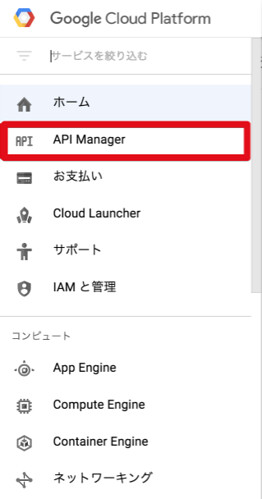
メニューが表示されますので、「API Manager」をクリック。
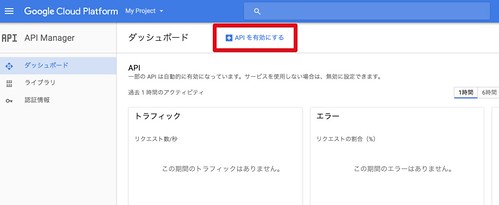
「APIを有効にする」をクリック
検索フォームが表示されるので、「Cloud Vision API」と入力します。
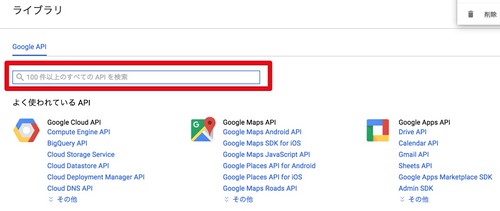
「Google Cloud Vision API」が表示されるはずなのでクリック
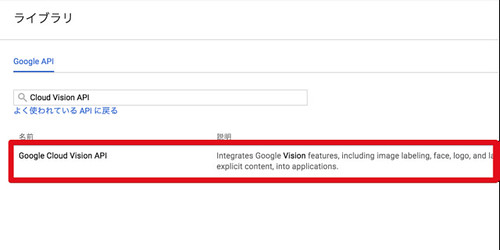
「有効にする」をクリック
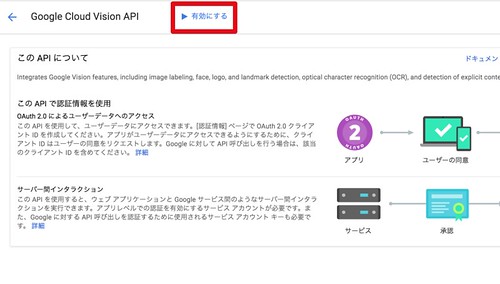
続いて認証情報の設定を行います。左側メニューの「認証情報」をクリック。
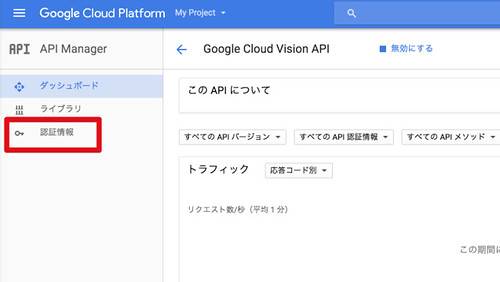
「認証情報を作成」からAPIキーを選択
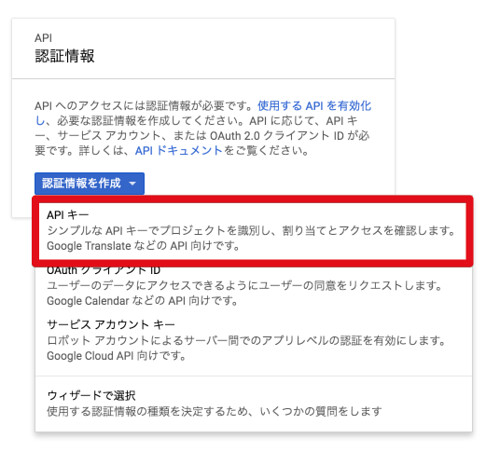
作成したAPIキーが表示されます。
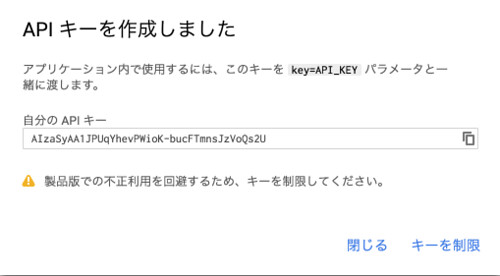
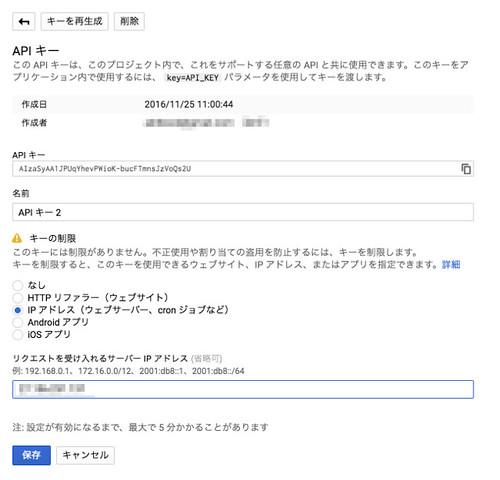
セキュリティを高めるために、「キーを制限」をクリックしてAPIへのアクセス制限をしておきましょう。今回はサーバーからアクセスさせたいため、「IPアドレス」を選択肢、リクエストを受け付けるIPアドレスを入力します。
物体検知 (LABEL_DETECTION)を試してみる
無事にAPIキーを取得できたら、実際に動作を確認してみます。サンプルコードは以下の通りです。
from base64 import b64encode
from os import makedirs
from os.path import join, basename
from sys import argv
import json
import requests
ENDPOINT_URL = 'https://vision.googleapis.com/v1/images:annotate'
RESULTS_DIR = 'jsons'
makedirs(RESULTS_DIR, exist_ok=True)
def make_image_data_list(image_filenames):
img_requests = []
for imgname in image_filenames:
with open(imgname, 'rb') as f:
ctxt = b64encode(f.read()).decode()
img_requests.append({
'image': {'content': ctxt},
'features': [{
'type': 'LABEL_DETECTION',
'maxResults': 10
}]
})
return img_requests
def make_image_data(image_filenames):
imgdict = make_image_data_list(image_filenames)
return json.dumps({"requests": imgdict }).encode()
def request_ocr(api_key, image_filenames):
response = requests.post(ENDPOINT_URL,
data=make_image_data(image_filenames),
params={'key': api_key},
headers={'Content-Type': 'application/json'})
return response
if __name__ == '__main__':
api_key, *image_filenames = argv[1:]
if not api_key or not image_filenames:
print("""
適切にAPIキーとイメージファイルを指定してください。
$ python cvapi.py api_key image.jpg""")
else:
response = request_ocr(api_key, image_filenames)
if response.status_code != 200 or response.json().get('error'):
print(response.text)
else:
for idx, resp in enumerate(response.json()['responses']):
imgname = image_filenames[idx]
jpath = join(RESULTS_DIR, basename(imgname) + '.json')
print (json.dumps(resp, indent=2))実行方法は以下のようにコマンドを実行します。
% python3.5 cvapi.py APIキー 画像ファイル名まずは以下の画像で試してみます。

{
"labelAnnotations": [
{
"mid": "/m/05r5c",
"score": 0.97654432,
"description": "piano"
},
{
"mid": "/m/04szw",
"score": 0.9113102,
"description": "musical instrument"
},
{
"mid": "/m/011_f4",
"score": 0.86833465,
"description": "string instrument"
},
{
"mid": "/m/02wfc4",
"score": 0.82297486,
"description": "fortepiano"
},
{
"mid": "/m/012lk9",
"score": 0.81312376,
"description": "player piano"
},
{
"mid": "/m/0bs7_0t",
"score": 0.80425763,
"description": "electronic device"
},
{
"mid": "/m/05148p4",
"score": 0.8033424,
"description": "keyboard"
},
{
"mid": "/m/07c1v",
"score": 0.797169,
"description": "technology"
},
{
"mid": "/m/01pmyz",
"score": 0.75289851,
"description": "digital piano"
},
{
"mid": "/m/01s0ps",
"score": 0.7401467,
"description": "electric piano"
}
]
}ちゃんとピアノと認識してくれています。続いては以下のクマのおもちゃで試してみます。

{
"labelAnnotations": [
{
"mid": "/m/06fvc",
"description": "red",
"score": 0.9064768
},
{
"mid": "/m/0138tl",
"description": "toy",
"score": 0.70904654
},
{
"mid": "/m/02wbm",
"description": "food",
"score": 0.69156486
},
{
"mid": "/m/0c9ph5",
"description": "flower",
"score": 0.67659795
}
]
}悪くない結果です。クマとは認識してくれませんでしたが、「赤」と「おもちゃ」を認識してくれています。最後にぐんまちゃんで試してみます。

{
"labelAnnotations": [
{
"mid": "/m/01sdr",
"score": 0.96886373,
"description": "color"
},
{
"mid": "/m/088fh",
"score": 0.80589223,
"description": "yellow"
},
{
"mid": "/m/0153bq",
"score": 0.75131446,
"description": "mascot"
},
{
"mid": "/m/0c9ph5",
"score": 0.54446042,
"description": "flower"
},
{
"mid": "/m/0138tl",
"score": 0.52193815,
"description": "toy"
},
{
"mid": "/m/0hr5k",
"score": 0.52063161,
"description": "festival"
},
{
"mid": "/m/0250x",
"score": 0.50722837,
"description": "costume"
}
]
}んー、微妙。
文章検出(TEXT_DETECTION)を試してみる
続いて画像から文章検出するTEXT_DETECTIONを試してみます。スクリプトは以下の通り。
from base64 import b64encode
from os import makedirs
from os.path import join, basename
from sys import argv
import json
import requests
ENDPOINT_URL = 'https://vision.googleapis.com/v1/images:annotate'
RESULTS_DIR = 'jsons'
makedirs(RESULTS_DIR, exist_ok=True)
def make_image_data_list(image_filenames):
img_requests = []
for imgname in image_filenames:
with open(imgname, 'rb') as f:
ctxt = b64encode(f.read()).decode()
img_requests.append({
'image': {'content': ctxt},
'features': [{
'type': 'TEXT_DETECTION',
'maxResults': 1
}]
})
return img_requests
def make_image_data(image_filenames):
imgdict = make_image_data_list(image_filenames)
return json.dumps({"requests": imgdict }).encode()
def request_ocr(api_key, image_filenames):
response = requests.post(ENDPOINT_URL,
data=make_image_data(image_filenames),
params={'key': api_key},
headers={'Content-Type': 'application/json'})
return response
if __name__ == '__main__':
api_key, *image_filenames = argv[1:]
if not api_key or not image_filenames:
print("""
適切にAPIキーとイメージファイルを指定してください。
$ python cvapi.py api_key image.jpg""")
else:
response = request_ocr(api_key, image_filenames)
if response.status_code != 200 or response.json().get('error'):
print(response.text)
else:
for idx, resp in enumerate(response.json()['responses']):
imgname = image_filenames[idx]
jpath = join(RESULTS_DIR, basename(imgname) + '.json')
print(resp['textAnnotations'][0]['description'])使用する画像は以下の夏目漱石の坊ちゃんの冒頭部分を画像にしたものを使用してみました。

実行結果は以下の通り。
坊っちゃん
夏目漱石
+目次
てっぽう
譲りの無鉄砲で小供の時から損ばかりしている。小学校に居る時分学校の二階から飛び降りて 週間ほど腰を抜かした事がある。なぜそんな無闇をしたと
聞く人があるかも知れぬ。別段深い理由でもない。新築の二階から首を出していたら、同級生の一人が冗談に、いくら威張っても、そこから飛び降りる事は出
来まい。融やーい。と囃したからである。小使に負ぶさって帰って来た時、おやじが大きな眼をして二階ぐらいから飛び降りて腰を抜かす奴があるかと云っ
たから、この次は抜かさずに飛んで見せますと答えた。
親類のものから西洋製のナイフを貰って奇麗な刃を日に翳して、友達に見せていたら、 人が光る事は光るが切れそうもないと云った。切れぬ事があるか
何でも切ってみせると受け合った。そんなら君の指を切ってみろと注文したから、何だ指ぐらいこの通りだと右の手の親指の甲をはすに切り込んだ。幸ナイフ
が小さいのと、親指の骨が堅かったので、今だに親指は手に付いている。しかし創痕は死ぬまで消えぬ。ほぼ完璧!すばらしい精度です。もう少し判別しづらい画像を使ってみます。

大人の
きのこの山
厳選カカオ素晴らしい!
まとめ
Cloud Vision APIの有用性を改めて確認できましたので、これを使って何かサービスを作ってみようかと思います。無料制限があるので、まずは個人用に作ってみようかな。

Google Cloud Visionを使ってみようとググっていたら本記事にたどりつきました。
サンプルコード、試させていただきました。
ありがとうございます。
TEXT_Detection、いいですね。使えます。OCR不要かという感じ。
見てわかるTCP/IPの著者とわかり、びっくり。
おぉー、といった感じです。
今度、まったりと話したいですね。